Model 성능 평가 metric
(수업 과제였는데, 그냥 그대로 묻히기가 아까워 가져옴)
네트워크의 성능을 분석하기 위해서 여러 성능 평가 지표가 쓰이는데, 그 중 대표적인 것으로 Accuracy, F1 Score, Sensitivity, Specificity, Precision과, 복합적인 성능 지표로 AUC와 MCC의 성능 지표가 있습니다. 어떠한 모델이 결과를 출력하게 되면, 예측한 값의 positive, negative data가 있고, 해당 값에 대한 실제 positive, negative data가 존재하게 되기에 True Positive, False Positive, False Negative, True Negative 이렇게 4가지의 결과값이 나오게 됩니다. 이때, Accuracy(ACC, 정확도)는 다음과 같이 나타낼 수 있습니다.


즉, 모델이 출력한 모든 결과값 중에서 예측값과 실제값이 얼마나 동일한 지를 가리키는 값입니다. 그러나 위와 같은 경우, 데이터 불균형(data imbalance)을 가지는 이진 분류 모델에서는 수치상으로만 좋은 값이 나올 수가 있습니다. 예를 들어 TP = 1000, FP = 5, FN = 35, TN = 10 인 경우,

으로 높은 값이 나올 수가 있습니다. 그러나 해당 값이 암과 관련되었다면 실제 암을 가지고 있으나 Negative이라고 잘못 진단한 환자가 35명이나 존재하여 Negative를 제대로 예측하지 못하는 상황이 나오게 됩니다. 이렇게 사람이 직접 보아도 Negative 예측 오답율이 높아 납득이 되지 않는 상황이지만 수치상으로는 높게 나올 수가 있습니다. 이러한 경우 Sensitivity와 Specificity 값을 이용하여 F1 Score, 또는 AUC, MCC를 평가지표로서 사용할 수 있습니다. 우선 Sensitivity(Recall), Specificity, Precision은 다음과 같이 나타낼 수 있습니다.

Sensitivity(민감도), 또는 Recall(재현율)은 실제 positive값 중, 얼마나 많은 값을 positive으로 예측하였는지를 나타냅니다. 따라서 Sensitivity는 True Positive Rate (TPR)이라고 표현하기도 합니다. Specificity(특이도)는 negative으로 예측한 값 중, 실제로 negative인 값을 나타냅니다. Precision(정밀도)은 positive으로 예측한 값 중, 실제로 positive인 값을 나타냅니다. 따라서 True Negative Rate (TNR)이라고 표현하기도 합니다. F1-score는 이중 Recall 값과 Precision의 조화평균으로 계산되는 지표이며, 다음과 같이 나타낼 수 있습니다.

해당 지표는 앞서 언급한 데이터 불균형으로 인한 정확도(Accuracy)가 성능 평가 지표로써 역할을 제대로 할 수 없을 때 성능지표로 사용할 수가 있습니다. Precision과 Recall 두 값 중 하나가 좋지 않아 0에 가까워질수록 지표에 반영될 수 있게 됩니다. 모든 값은 0~1 사이의 값을 가지며, 1에 가까워질수록 성능이 좋다는 것을 의미합니다. 그러나 F1-score는 TN 값을 고려하지 않기에 모델의 분류 결과가 FN이 TN보다 많을 경우에도 TP가 압도적으로 많게 되면 높은 성능이라고 평가하여 사람들로 하여금 잘못된 선택을 내릴 수가 있습니다. 따라서 불균형한 데이터의 모델 성능을 더욱 적절히 평가하기 위해 AUC, MCC 지표가 사용됩니다. False Positive Rate (FPR)는 실제 negative값 중, 잘못 positive(false positive)으로 나타낸 값입니다. 식으로는
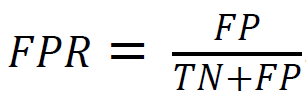
과 같이 나타낼 수 있는데, 이는

으로 표현될 수 있습니다.

AUC의 값이 1에 가까워질수록 해당 모델은 이상적인 분류 성능을 보이고 있음을 가리키며, 0.5에 가까워질수록 분류 모델의 성능이 나빠지는 것을 보여줍니다. AUC 지표는 의료 관련 시험에서도 많이 쓰입니다. 모델이 의학적인 진단을 보조해주는 소프트웨어로서 의료계에서는 AUC가 0.8 (80%) 이상일 때부터 모델의 평가 성능이 좋다고 판단되고 있습니다.(출처 1) 또한 최근에는 보조 진단 소프트웨어로서 AUC의 성능을 0.85~0.87인 모델을 개발하는 것을 목표로 하고 있습니다. (출처 2) 그리고 해당 값보다 좋을 경우에 비로소 임상실험의 보조 진단 소프트웨어로서 사용할 수 있다고 합니다. AUC의 값이 1에 가까워질수록 ROC curve는 좌측상단 끝에 가까워지면서 크게 휘어지게 됩니다.
불균형한 데이터를 사용하는 모델에 대한 또다른 지표로서는 Mathews Correlation Coefficient (MCC)가 있습니다. 해당 지표에 대한 수식은 다음과 같이 나오게 됩니다.

해당 지표는 F1-score와는 달리 confusion matrix의 모든 값(TP, TN, FP, FN)을 고려하기에 positive와 negative을 모두 잘 분류하는 경우에 높은 점수가 나오게 됩니다. 따라서 F1-score에서는 높은 성능점수가 나오게 되더라도 MCC에서는 낮은 성능점수가 나올 수 있습니다. MCC는 -1~0~+1 사이의 값을 점수로 나타나게 되며, +1인 경우 완벽한 예측, -1인 경우 완전 반대 예측, 0일 경우 랜덤한 예측으로 성능을 평가하게 됩니다. 또한 positive와 negative를 대칭 취급하기에 predicted value의 positive와 negative 값을 서로 바꿔도 동일한 성능 점수를 출력합니다. 따라서 F1-score와는 달리 positive, negative 데이터 불균형이 역전되어도 동일한 성능점수가 나오게 되어 모델의 성능을 적절히 평가하기에 좋은 지표입니다.
출처 1: 식품의약품안전평가원 의료기기심사부 첨단의료기기과, “뇌 영상검출, 진단보조 소프트웨어 안전성, 성능 및 임상시험계획서 평가 가이드라인”. 2020-12.
출처 2: 국립암센터, “질병 진단 이미지 AI 데이터 구축 가이드라인”, 2021-11.