
Jun Station 준스테이션
YOLO v4 정리 본문
YOLO (You Only Look Once) Version 4 정리 글 링크:
hoya012.github.io/blog/yolov4/
YOLOv4:Optimal Speed and Accuracy of Object Detection Review
YOLOv4:Optimal Speed and Accuracy of Object Detection 논문을 리뷰하였습니다.
hoya012.github.io
YOLOv4 : Object detection의 최적의 속도와 정확도
이번 포스팅에서는 YOLOv4의 논문을 리딩해보겠다. 저번 포스팅에서도 최대한 논문의 전반적인 내용을 다루면서 쉽게 설명하려고 노력 했으나.. 여간 어려운 작업이 아닐 수 없다. 각설하고 YOLOv4
keyog.tistory.com
YOLO v4 리뷰 : Optimal Speed and Accuracy of Object Detection (공부중)
작성자 : 한양대학원 융합로봇시스템학과 석사과정 유승환 오늘은 저번달에 나온 따끈 따끈한 YOLO의 새로운 버전, YOLO v4에 대해 공부해보겠다! 아카이브 기준으로 2020년 4월 23일에 YOLO v4 논문이
ropiens.tistory.com
YOLOv4에 들어가기 전에 범용적이게 사용되는 기술 (추후에 다시 좀 살펴볼 것들):
Batch Normalization:
WRC: Weighted Residual Connections
CSP: Cross Stage Partial Connections
CmBN: Cross mini-Batch Normalization
SAT: Self Adversarial Training
Mish-activation
소개:
- Detector의 정확도의 향상만이 정답이 아니다.
-> 가장 좋은 성능을 가진 object detection은 realtime이 불가능 & 멀티 GPU가 필요.
3.4 YOLOv4
Backbone: CSPDarknet53
Neck: SPP, PAN
Head: YOLOv3

Bag of Freebies (BoF):
- Data augmentation, Loss function, Regularization 등 학습에 관여하는 요소
- Training cost를 증가시켜서 정확도를 높이는 방법
- Inference cost의 변화 없이 성능 향성(better accuracy)을 꾀할 수 있는 기법
-> 다양한 기법을 전부 동원했다:

| Data Augmentation (데이터 증강) 기법 | - Image의 일부 영역에 box를 생성하고 해당 영역을 0~255의 random한 값으로 채우는 Random erase - 0으로 채우는 CutOut - 두 image와 label를 alpha blending하는 MixUp - CutOut과 MixUp을 응용한 CutMix - Style-transder GAN |
| Regularization 기법 | - DropOut - DropPath - Spatial DropOut - DropBlock |
| Bounding Box Regression 기법에 사용되는 Loss function | - MSE - IoU - Generalized IoU - Complete IoU - Distance IoU |
Bag of Specials:
- 학습에서는 Forward pass만 영향을 주고, 학습된 모델에 대해 inference를 하는 부분에 관여를 한다는 점이 bag of freebies와 차이 (이게 뭔말이야)
- Architecture 관점에서의 기법들이 메인
- Post processing이 포함
- 오로지 inference cost만 증가시켜서 정확도를 높이는 기법
- Inference cost가 조금 상승하지만, 성능 향상이 되는 딥러닝 기법

| Enhance Receptive Field | - SPP - ASPP - RFB |
| Feature Integration | - Skip-connection - Hyper-column - Bi-FPN |
| 최적의 Activation Function | - P-ReLU - ReLU6 - Mish |
------------------------------------------------------------------------
< YOLOv4 Architecture>
(구체적인 설명들은 링크 사이트에서 확인할 것)
YOLO의 고질적인 문제: 다양한 작은 object들을 잘 검출하기 위해 input resolution을 크게 사용함.
기존: 224, 256 -> YOLOv4: 512 => 정확도 향상 & 속도 저하 문제
-> 따라서 2020 CVPR Workshop에 발표예정인 CSPNet 기반의 backbone을 설계하여 사용
Architecture
1. Backbone: CSP-Darknet53
2. Neck: SPP (Spatial Pyramid Pooling), PAN (Path Aggregation Network)
3. Head: YOLOv3
(그니깐 YOLOv4를 알기 위해서는 얘네들을 또 공부할 필요가 있다는 말이네)
기존: DenseNet
논문 제안: CSP DenseNet


기존의 DenseNet: Dense Block과 Transition Layer로 구성
Dense Block: - k개의 Dense Layer들을 포함
- 첫번째(i 번째)의 dense layer에서 x_0(연보라색 블록)과 x_1(연하늘색 블록)이 결합 (concatenated)
- 이 결합된 output은 두번째 (i+1 번째) dense layer의 input이 됨
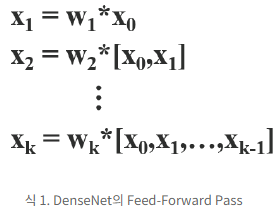
이때,
* : convolution 연산자
[a, b] : a와 b를 결합
w_k : k번째 dense layer의 weight(가중치)
x_k : k번째 output

Back Propagation
f : 가중체 업데이트에 관한 함수
g_i : i 번째 dense layer로 전파되는 gradient (기울기)
-> 블로그에서는 이 식에서 많은 양의 기울기 정보가 서로 다른 dense layer들의 가중치를 업데이트하기 위해 재사용된다고 한다.
-> 서로 다른 dense layer들이 복사된 gradient 정보를 반복적으로 학습

논문에서 제안하는 CSP DenseNet (Cross Stage Partial DenseNet): Partial Dense Block과 Partial Transition Layer로 구성
Partial Dense Block: Dense Layer 1의 feature map(연보라색 블록, 원문에서는 base layer)
채널을 통해 두 부분으로 분리

Former (x_0') : stage의 끝인 partial transition layer와 직접적으로 연결
Latter (x_0") : 다음 dense block들을 거치게 됨
설계 목적:
| 1. 기울기 path 증가 | split (base layer의 분리) + merge (transition block에서 통합) => gradient paths의 수가 2배 Cross-Stage 전략으로 인해 결합을 위해 복사는 feature map (연보라색 블록)을 사용함으로써 생기는 단점을 완화 (그렇다고 한다) |
| 2. 각 layer의 밸런스 맞춘 계산량 | DenseNet의 base layer (연보라색 블록)의 채널수 는 growth rate보다 더 크다. Partial dense block에서 dense layer 연산에 관여하는 base layer의 채널들이 원래 값의 절반 밖에 차지하지 않다. => DenseNet보다 계산량의 2배를 효율적으로 감소할 수 있다. (그렇다고 한다) |
| 3. 메모리 traffic 감소 | => Partial Dense Block은 네트워크의 메모리 traffic의 절반을 저장할 수 있음 (그렇다고 한다... 공부를 더 해야 뭔말인지 알아들을 것 같다) |
Partial Transition Layer 과정
1. Dense Layer의 output인 [x_0", x_1, ... x_k]은 transition layer(회색 블록)를 겪게(undergo)된다고 한다.
2. 이 transition layer의 output인 x_T는 x_0'과 결합되어 x_U를 생성. CSP-DenseNet의 feed-forward pass와 가중치 업데이트 방정식은 아래와 같다.



식4의 초록색 상자: dense layer에서 오는 gradient(기울기) g들이 분리되어 각각 w_T, w-U에 통합되어 있음
w_T와 w_U는 gradient 정보가 중복되지 않는다

블로그 글쓴이 결론:
성과적 관점: YOLOv3 대비 정확도(AP)를 10% 포인트나 끌어올림, 실시간을 고려함.
연구적 관점: 다소 주먹구구식 이 방법 저 방법 다 끌어모아서 합친 모델.
실용적 관점: Single GPU로 학습, 테스트 모델 배포를 가능하게 함. -> 가장 큰 장점이자 논문의 main goal인 것 같음.
Object Detection 관련 다양한 기법들을 제시 -> Object Detection을 공부하여 Kaggle 등의 대회를 준비하
는 사람들에게 아이디어를 얻기에 좋음.
-> 즉 지금 내가 공부하기에 좋음! (물론 딴 분야도 얼른 공부해야지......)
최신 알아두어야 할 용어들:
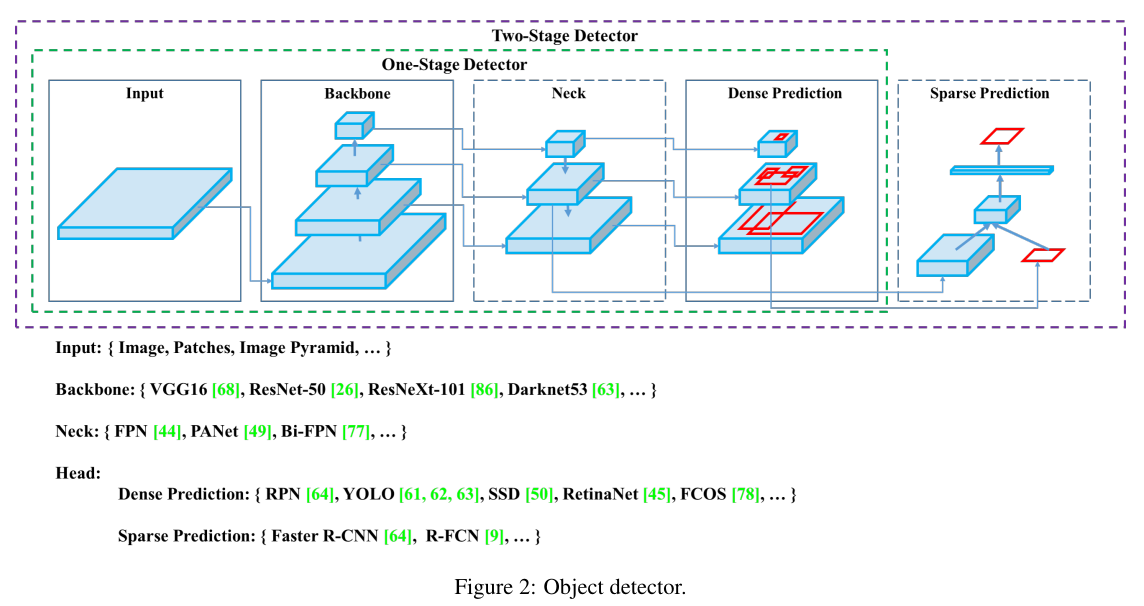
최신 detector: Backbone와 Head (& Neck)로 구성된다.
Backbone: 입력 이미지를 feature map으로 변형시켜주는 부분.
예) ImageNet dataset으로 pre-trained시킨 VGG16, ResNet-50 등
Head: Backbone에서 추출한 feature map의 location 작업을 수행하는 부분
Predict Classess 와 Bounding Boxes 작업이 수행됨
Dense 와 Sparse Prediction 두 가지로 나뉘어짐
- Dense Prediction
-> One-Stage Detector가 head로 사용함. YOLO, SDD 등
- Predict Classes와 Bounding Box Regression 부분이 통합되어 있음
- Sparse Prediction
-> Two-Stage Detector가 head로 사용함. Faster R-CNN, R-FCN 등
- Predict Classes와 Bounding Box Regression 부분이 분리되어 있음
참고사항: 저자의 다른 아이디어

'Networks (& Architectures) > YOLO 계열' 카테고리의 다른 글
| YOLO 기초 개념 정리 (0) | 2021.02.09 |
|---|
