
Jun Station 준스테이션
YOLO 기초 개념 정리 본문
What is YOLO?

물체 인식(Object Detection)을 수행하기 위해 고안된 심층 신경망으로서, Bounding Box Coordinate (테두리 상자 조정)과 Classification (분류)을 동일 신경망 구조를 통해 동시에 실행하는 통합인식 (Unified Detection)을 구현하는 것이 특징
YOLO Detection System

(1). Input image를 448 x 448 으로 resize
(2). 해당 image를 한 번의(single) convolutional network에 통과
-> 합성곱 신경망을 단 한 번만 통과시킨다는 것이 핵심
(3). Model의 Confidence에 의해 결과 값(resulting detections)을 여과(threshold)
Unified Detection

(1). The system divides the input image into an S x S (7 x 7) grid.
(2). Each grid cell predicts B bounding boxes and Confidence scores for those boxes, and C class probabilities.
- Confidence = Pr(Object) * IOU (truth / pred.)
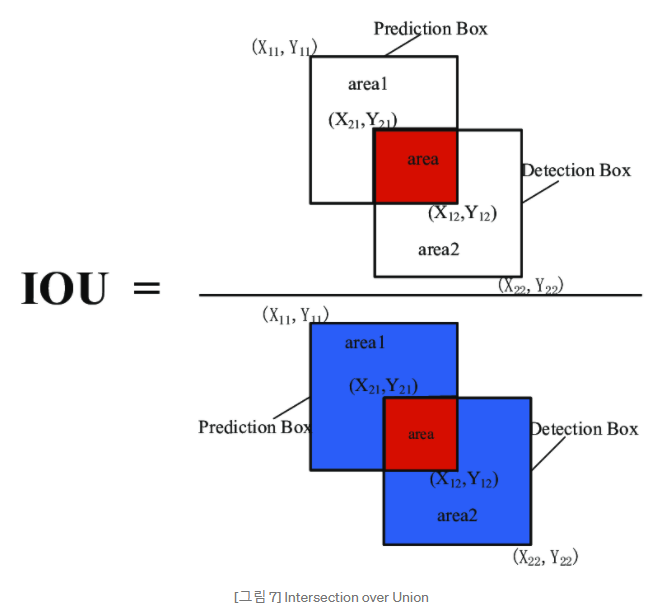
=> 해당 cell 에 어떠한 object도 없을 경우 (Bounding box에 배경만 있을 경우) : 0
=> 그 외에는 predicted box와 ground truth 간의 IoU 만큼의 값을 가짐
- Bounding box = 각 box는 5개의 predictions을 가짐: x, y (x와 y 좌표), w (가로), h (세로), and
confidence
- (x, y) 좌표: box center 위치
- width and height: predicted relative to the whole image
- confidence: IOU between the predicted box(학습 데이터의 예측한 박스) and any
ground box(학습 데이터의 바운딩 박스)
(3). These predictions are encoded as an S x S (B * 5 + C) tensor.
YOLO Architecture (구조)

Detection network:
-
24개의 Convolutional Layers와 2개의 Fully Connected Layers가 연결된 구조
-
크게 Pre-trained Network, Training Network, Reductrion Layer 영역으로 구분
< 간단 설명 >


흰 박스 : 입력
빨간 박스 : CNN (조그마한 네모가 Conv. Layers, 큰 네모가 feature map)
Feature map 크기는 Conv. Layers을 거칠 때마다 크기가 작아진다.
초록 박스 : Fully Connected Layer
마지막 박스: Prediction Tensor -> 이것을 바탕으로 학습, Regression 및 Classification을 수행
7 x 7 x 30의 grid (7 x 7이 30개의 길이)
(B*5 + C )= 30에서 : C는 Class의 개수, 해당 paper에서는 C=20
B*5 =10, B = 2, B는 각각의 grid에 갖는 Bounding Box 후보의 개수,
paper에서는 grid별로 2개씩 가지겠다고 함
< 상세 설명 >

Pre-trained network (주황색 테두리):
- GoogLeNet을 이용하여 ImageNet 1000 class dataset을 사전에 학습한 결과를 Fine-Tuning 한 네트워크
- 총 20개의 Convolutional Layer들로 구성
- 해당 paper에서는 88%의 정확도를 사전에 학습
- 448 x 448 x 3 의 이미지를 입력 데이터로 받음
-> ImageNet의 dataset은 224 x 224 의 크기이나, 객체 감지를 학습할 때에는 선명한 이미지보다 경계선
이 흐릿한 이미지가 더 학습이 잘된다고 하여 Scale Factor를 2로 설정한 값
Reduction Layer (오렌지색 테두리):
- GoogLeNet의 기법을 응용, 연산량은 감소, 층은 깊게 쌓음
- Conv Layer를 통과할 때 사용하는 Filter 연산은 수행시간이 길다. 따라서 한없이 네트워크를 깊게 쌓을 수는 없다.
-> 이러한 문제를 해결하기 위해 ResNet, GoogLeNet 등의 기법이 제안됨
Training Network (파란색 테두리):
- Pre-trained Network에서 학습한 feature를 이용하여 Class probability와 Bounding box를 학습하고 예측
- YOLO의 예측모델은 S x S x (B*5 + C )
-- PASCAL VOC dataset은 20개의 class를 제공하기에 C = 20
-- grid cell은 7개로 정의됨. 따라서 총 1470개의 값이 출력
YOLO 모델의 Cost Function (Loss Function)

Prediction Tensor: ( (x, y, w, h, s)*B + (C) )
x, y, w, h: Bounding Box 관련 정보
s: Confidence 관련 정보
*B: 각 grid 별 Bounding Box 개수만큼 곱한다
+(C): Class 만큼의 길이를 갖는다
첫번째 항: x, y 관련 항
두번째 항: w, h 관련 항
세번째 항: Confidence 관련 항, Object가 없을 시 penalty를 준다.
대표적으로, box 안에 물체가 없는 경우에는 Confidence Score를 0으로 만들기 위해
Localization Error에 더 높은 penaly를 부과한다.
네번째 항: Class loss 관련 항

| S | grid cell의 크기, 행렬이기에 전체 grid cell의 개수는 S² |
| B | S_i 셀의 Bounding box |
| x, y, w, h | Bounding box의 좌표 및 크기 |
| C | 각 grid cell이 구분한 class |


| 1번 (λ_coord) | - coordinates(x,y,w,h)에 대한 loss와 다른 loss들과의 균형을 위한 balancing parameter. - 5로 설정된 λ_coord 변수로서 Localization 에러에 5배 더 높은 패널티를 부여하기 위해서 사용. - 예로 보면 5번 테두리에서 분류에 따른 오차는 가중치가 존재하지 않는 반면에 바운딩 박스의 에러에는 5배 더 높은 패널티가 부여되어 있다. |
| 2번 | - if문과 동일한 역할을 한다. - i번째 셀의 j번 bounding box만을 학습하겠다는 의미로 사용. - 그러나 모든 셀에 대해서 bounding box 학습이 일어나지 않고 각 객체마다 IOU가 가장 높은 bounding box인 경우에만 패널티를 부과해서 학습을 더 잘하도록 유도한다. |
| 3번 (λ_noobj) | - obj가 있는 box와 없는 box간에 균형을 위한 balancing parameter. (일반적으로 image내에는 obj가 있는 cell보다는 obj가 없는 cell이 훨씬 많으므로) - 해당 셀에 객체가 존재하지 않는 경우, 즉 배경인 경우에는 bounding box 학습에 영향을 미치지 않도록 0.5의 가중치를 곱해주어서 패널티를 낮춘다. |
| 4번 | 2번(연두색 박스)와는 반대의 경우로 i번째 셀과 j번째 bounding box에 객체가 없는 경우에 수행 한다는 의미. |
| 5번, 6번 | 바운딩 박스와는 상관 없이 각 셀마다 클래스를 분류하기 위한 오차이다. |
위 Loss Function을 이용하여 network를 학습할 뒤, 예측을 하면 각 cell마다 여러 장의 Bounding Box가 생김.
-> 그 중 물체의 중심에 있는 cell이 보통 Loss Function의 연두색 2번에 해당.
- 물체의 중심을 중심으로 그려진 bounding box는 confidence score가 높게 나옴
- 반대로, 물체의 중심으로부터 먼 cell이 만드는 bounding box는 score가 더 작게 나옴.
-> 최종적으로 여러 개의 bounding box를 합치는 Non-max suppression 과정을 거쳐 해당 이미지의 객체를 탐지할 수 있게된다.

참고 사이트 링크:
www.youtube.com/watch?v=8DjIJc7xH5U
You Only Look Once — 다.. 단지 한 번만 보았을 뿐이라구!
이번 포스팅에서는 객체 탐지(Object Detection)분야에서 많이 알려진 논문인 “You Only Look Once: Unified, Real-Time Object Detection (2016)”을 다룬다[1]. 줄여서 흔히 YOLO라고…
medium.com
curt-park.github.io/2017-03-26/yolo/
[분석] YOLO
Paper study of YOLO published in May 2016
curt-park.github.io
'Networks (& Architectures) > YOLO 계열' 카테고리의 다른 글
| YOLO v4 정리 (0) | 2021.01.26 |
|---|
